
English Version (splitted in two parts) on Pulse:
https://www.linkedin.com/pulse/data-science-during-coronavirus-times-part-1-andrea-pescino/
Da anni cerco di impegnarmi per trasferire il valore del data driven alle organizzazioni con le quali collaboro. Oggi il mondo parla di Intelligenza artificiale partendo dal tema dell’apprendimento automatico (machine learning).
Grazie all’enorme diffusione di dati estremamente vari e ricchi, sia per dimensione che per copertura e granularità, si possono fare analisi spesso semplici che possono portare grande valore ed aiutare decisioni informate e non basate su percezioni o esperienze pregresse (magari basate su situazioni diverse).
Fatta questa anticipazione, mi sono trovato qualche giorno fa nel mezzo dell’esplosione di questo fenomeno, dove l’Italia è stata il primo paese europeo colpito dell’epidemia di COVID-19.
Abbiamo assistito ad una graduale diffusione del virus: prima in alcune zone della Lombardia, che ha portato inizialmente ad una zona rossa (10 comuni lombardi ed 1 veneto) il 23 febbraio 2020 , quindi alla chiusura delle scuole in 6 regione italiane il 25 febbraio 2020, per arrivare all’8 marzo 2020 all’estensione della zona rossa all’intera Lombardia con l’aggiunta di diverse province del Piemonte, Emilia-Romagna, Veneto e Marche.
Il 9 marzo un ulteriore decreto restrittivo definiva il lockdown nell’intera nazione, ed il 12 marzo un ultimo decreto riduceva l’apertura degli esercizi commerciali.

Nel contempo l’analisi dei primi dati e del progresso del contagio ha portato il Dipartimento della Protezione Civile (DPC) a rilasciare comunicati ed informazioni strutturate e, dopo alcune iniziative di informatici e data scientist, a rilasciare un repository GitHub con tutti i dati ufficiali aggiornati in formato machine readable.
Qui un plauso al DPC, perché condividere contenuti è di grande valore, specie nell’esigenza di avere informazioni rapide e affidabili. Averle condivise in un repository pubblico ed accessibile ha fatto sì che diversi contributori aiutassero a definire meglio, correggere errori e proporre migliorie.
In principio si avevano a disposizione solo dati meno granulari e dettagliati, per il nostro paese, raccolti e validati dal John Hopkins University center for systems science and engineering (JHU CSSE) che forniva informazioni sull’andamento dell’epidemia in tutto il mondo.
Grazie a questa prima apertura del JHU prima, del DPC dopo, diverse altre realtà hanno cominciato a diffondere i dati locali come EU con (European Union Center for Disease Control EUCDC) o UK con Public Health England
Dai nostri dati italiani, aperti e disponibili, si sono potute fare dashboard con maggiori capacità di informazione e di interazione come questa, realizzata dall’amico Andrea Benedetti di Microsoft.
Anche Andrea, dopo una prima realizzazione “di corsa”, ha aperto un repository GitHub ed ha ricevuto il supporto di diversi professionisti IT che l’hanno fatta crescere e migliorare, e, soprattutto ,si è potuto cominciare a fare delle previsioni o proiezioni credibili, sia per capire la crescita di questo fenomeno che per definire o confermare parametri che sono e saranno fondamentali per la sua gestione futura.

L’idea che è maturata quindi il 9 marzo scorso, con il lockdown in Italia e che è stata condivisa con il Data science seed di Genova è stata:
- Riusciamo a prevedere l’andamento di questo fenomeno in Liguria (la regione nella quale viviamo e che ha l’età media (48,5 anni) più alta d’Italia)?
- Riusciamo a determinare la quantità di posti letto di rianimazione necessari?
- Quando questo fenomeno finirà o ridurrà la necessità di misure restrittive e contenitive?
Avevamo a disposizione molti dati per trovare un modello matematico che potesse fittare (quindi adeguarsi ai dati esistenti), anche se mancavano ancora parecchie informazioni.
Abbiamo quindi cominciato a cercarle anche chiedendo gli amici cinesi, che avevano già vissuto il fenomeno, e che sono stati rapidi e prodighi di informazioni e studi pubblicati (Grazie!).
Cerchiamo ora, a nostra volta, di condividere risultati e informazioni che cercheremo di strutturare meglio e produrre su repository aperti.
Undocumented cases: Diversi studi (riportati al termine del BLOG), con modalità differenti, hanno stabilito un parametro comune sui casi undocumented (pazienti infettivi non rilevati).
In questa patologia virale, la gran parte delle persone contagiate è asintomatica, o con sintomi molto lievi che possono facilmente essere confusi con patologie comuni.
Questo fa si che sia presente una grande quantità di contagiati, comunque infettivi, che non sapendo di esserlo favoriscono la progressione del contagio e non vivono le prime misure di contenimento (Quarantene).
Si è cercato di stabilire quale fosse la quantità di questi contagiati, ed il parametro che si ricava da due diversi studi è che al 95%, la percentuale di undocumented è tra 82% e 90%, (o nell’altro caso 81,8%-89.8%), quindi con una mediana all’86.2%.
Ciò significa che, il numero dei casi rilevati (ad esempio a ieri in Italia ne avevamo 47.021) rappresenta, in media, solamente il 13.8% dei casi reali contagiosi (applicando la proiezione all’Italia, nella giornata di ieri avremmo potuto rilevare 335.000 casi infettivi)
Tempo di incubazione: Inizialmente questo fenomeno è stato confuso con influenze stagionali. L’unico modo per rilevarlo con certezza è quello di effettuare un test apposito (PCR Test), che è stato realizzato e perfezionato dopo due settimane dalla prima identificazione, della malattia.
La Cina, dopo il primo periodo, nel quale ha gestito l’insorgenza dell’epidemia cercando di limitarla, ha fatto un uso estensivo di Big Data ed AI ed ha cominciato un programma di screening intensivo che gli ha consentito di definire in maniera più precisa il tempo di incubazione. La China National Health Commission (NHC) ha stimato quindi inizialmente un periodo di incubazione variabile tra i 10 e i 14 giorni.
In questi giorni, diversi enti stanno rilasciando la loro stima sui dati (è difficile in questa fase non controllabile stabilire il momento iniziale di esposizione all’agente virale).
Il WHO riporta che il periodo può andare dai 2 ai 10 giorni, mentre l’US CDC definisce dai 2 ai 14 giorni.
Questo significa che, se prendiamo una mediana di 5,1 giorni, dovremmo rilevare gli effetti delle misure restrittive al movimento in media dopo tale periodo.
Il 97,5% di coloro che ha sviluppato sintomi, comunque, lo ha fatto entro 11,5 giorni dall’infezione (quindi dopo questo periodo, gli effetti delle misure restrittive dovrebbero essere evidenti e significativi)
Tempi di decorso della malattia e ricovero in terapia intensiva (ICU)
Per poter stabilire con maggiore precisione il numero dei letti in terapia intensiva necessari, era necessario conoscere i tempi medi di decorso della malattia: dall’insorgenza dei primi sintomi, alla dispnea, al ricovero in terapia intensiva, fino al termine del ricovero (decesso o sopravvivenza).
Purtroppo non siamo riusciti ad ottenere un dataset disaggregato, questo avrebbe aiutato a raffinare ed adeguare le previsioni, ma uno studio recente pubblicato su Lancet identifica un parametro medio aggregato che consente di stabilire quanto tempo rimarrà mediamente occupato un letto in terapia intensiva per un paziente COVID.
In media, come tempo di occupazione abbiamo 7,5 gg per coloro che guariscono, e di 6,5 gg per i deceduti.
Su questo parametro sarebbe necessaria una valutazione No stress / Under stress del sistema sanitario, sia per rilevare a quale stadio del decorso vengono in media ospedalizzati i pazienti (è ragionevole pensare che sotto stress gli accessi in ospedale vengano ridotti per capienza), che per rilevare la varianza nei tempi di permanenza in terapia intensiva.

Significatività e clustering
Regione Liguria aveva identificato il primo caso il 25 febbraio 2020 (dal Dataset DPC), controllando le notizie sembra si riferisse ad una turista proveniente dal lodigiano (prima zona rossa). Il caso era nella provincia di Savona (Alassio).
La domanda a quel punto è: quanto può essere significativa una proiezione su una regione che, per quanto limitata come superficie, conta 1,55 mln di abitanti, specie considerando che la maggiore concentrazione di questi abitanti è nell’area metropolitana di Genova?
Sappiamo però che, in realtà, il numero dei contagiati in quella data era ben più alto:
Considerando il periodo di incubazione, e la percentuale degli undocumented, possiamo stimare quindi il numero dei contagiati infettivi, al 25 febbraio a 150 casi.
(Si verificano i dati del totale positivi al primo di marzo, 21 casi, e si considera che questi sono, in media il 13,8% dei casi totali effettivamente contagiosi).
Il cluster è quindi già significativo, e la mobilità sicuramente più ridotta (Un solo aeroporto regionale e due stazioni ferroviarie importanti) ci da elementi per fare una buona previsione.
Modellazione all’11 di marzo
Una volta raccolti questi parametri, avevamo il dataset del DPC per la Regione Liguria, che, all’11 di marzo, identificava 181 pazienti positivi, dei quali 108 ospedalizzati (56%), dei quali 34 (31% degli ospedalizzati, 19% dei casi totali) in Terapia intensiva.
Avevamo quindi la progressione dal 25 febbraio all’11 di marzo e si poteva cominciare a stabilire la curva che meglio si adattasse a questo andamento per definire il modello matematico della crescita.
La curva più adatta, per i fenomeni epidemici, è una curva logistica della quale era possibile stabilire il tasso di crescita:

La differenza di casi nel tempo si ottiene facendo crescere i casi giornalmente (unità di tempo) per un fattore (r), limitando la crescita nel momento in cui il numero di potenzialmente infettabili diminuisce (perché sono stati tutti infettati, guariti, deceduti).
In realtà il calcolo è molto più semplice di quanto l’equazione suggerisca ai non matematici: Nel nostro caso andiamo a variare il parametro fino a quando questo non “fitta” con l’andamento che avevamo a quel tempo:

Stabilito il parametro di crescita (1,20419), e valutato che, anche considerando tempo di incubazione (+6 giorni) e casi non documentati (86,2% del totale), si stavano stimando 5.136 casi, quindi lo 0,32% della popolazione Ligure, potevamo proiettare i giorni successivi sapendo che la crescita non sarebbe stata limitata, e la pendenza sarebbe stata coerente almeno fino al 17/19 di marzo, dato che le misure prese il 9 marzo e il 12 marzo non avrebbero avuto effetto nei numeri visto il tempo di incubazione stimato.

A quel punto si poneva la scelta di modellare gli altri parametri: Ospedalizzati, ammessi in terapia intensiva, guariti e deceduti.
C’erano diverse scelte che avevano tutte diverse suscettibilità:
Avremmo limitato il numero di test effettuati (Diventa difficile farlo a tutti al salire dei casi)? (aumentando quindi la percentuale relativa di ospedalizzati?)
Avremmo variato, per scelta o per necessità, le politiche di ammissione ospedaliera? Avremmo variato il tempo di permanenza in Terapia Intensiva?
La scelta finale è stata quella di modellare analogamente la curva, ma prevedendo degli aggiustamenti sulle percentuali identificate in Cina nella provincia di Hubei (quella di Wuhan).
Sulla base di questo sono state generate le proiezioni di:
- Ospedalizzati (Curva specifica adeguata)
- Terapia Intensiva (Calcolando che il numero viene decrementato delle ammissioni avvenute 9 giorni prima)
- Deceduti (curva statistica)

Ora, a distanza di circa 10 giorni dalla previsione possiamo verificare l’adeguatezza del modello e capire qualche elemento in più:
- Crescita e progressione
- Verifica (Empirica e statistica) della media del tempo di incubazione definito
- Indicazione su tempi medi di degenza in terapia intensiva
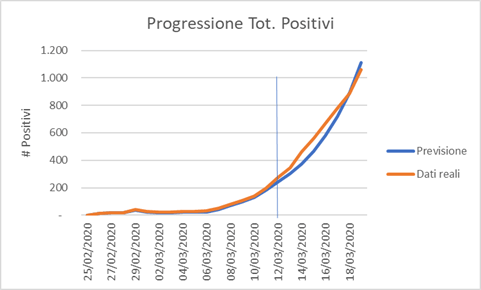


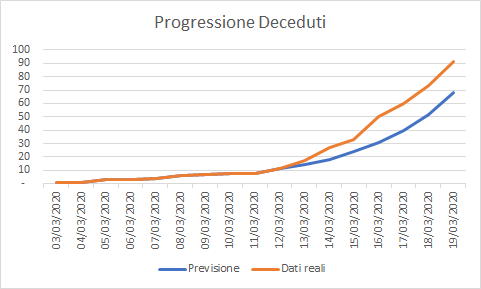
Il maggior numero di decessi è legato probabilmente all’età media della popolazione ligure (la più alta d’Italia) stante i tassi di mortalità rilevati in Cina per età e patologie pregresse.
Il maggior numero di decessi, dall’altra parte, compensa quasi esattamente il minor numero di posti di rianimazione necessari (per quanto non si può derivare una correlazione stretta su questa numerica limitata e, comunque, stimata).
Si vede inoltre come, per almeno 10 giorni dall’entrata in vigore delle prime misure restrittive del 9 marzo, e ad almeno 7 giorni dall’entrata in vigore delle misure maggiormente restrittive del 12 marzo, non si rileva alcuna diminuzione nella progressione del contagio.
Si nota, ma è un singolo elemento, come il 20 di marzo, il numero totale dei casi in Liguria era di 1.221, contro i 1.377 invece previsti, quindi una riduzione molto significativa, che si attende di confermare nella giornata odierna.
Questo potrebbe suggerire un primo impatto delle misure restrittive del 9 marzo (e quindi un tempo medio di incubazione di 11 giorni, come suggerito dalle analisi fatte in Cina), oppure un impatto delle misure del 12 marzo.
Nei prossimi giorni cercherò di riportare analoghe valutazioni su quelle che potrebbero essere le previsioni per il futuro, sia in termini di sviluppo della curva che in termini di potenziale riduzione delle misure di distanziamento sociale.
Grazie per ogni commento o integrazione che, se necessario, integrerò anche nella versione inglese del post.
Articoli e fonti consultate:
– Vital Surveillances: The epdemiologica Characteristics of an Outbreak of 2019 Novel Coronavirus Diseases (COVID-19) – China 2020
– Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: a retrospective cohort study
– Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV2). (2020)
– https://github.com/CSSEGISandData
– https://zenodo.org/record/3699624#.XnX2nohKgaZ
– https://www.worldometers.info/coronavirus/coronavirus-incubation-period/
– https://github.com/pcm-dpc/COVID-19
– Real estimates of mortality following COVID-19 infection (2020)
– Effect of delay in diagnosis on transmission of COVID-19 (2020)
– Insights from early mathematical models of 2019-nCoV acute respiratory disease (COVID-19) dynamics

Pingback: Lockdown, COVID e dati, quando finirà? | The Big Shift
Pingback: COVID – Curva di uscita | The Big Shift