Ciao a tutti, appassionati di tecnologia! Ultimamente si parla molto dei modelli di ragionamento: molti di essi sono già in grado di risolvere problemi matematici molto complessi, e c’è un crescente entusiasmo verso il raggiungimento rapido dell’AGI (Intelligenza Artificiale Generale). Ma prima di tutto, diamo un’occhiata a un argomento che sta facendo discutere la comunità dell’IA: la contaminazione dei dati nei modelli di linguaggio di grandi dimensioni (LLM). Non preoccupatevi; cercheremo di spiegare tutto in modo semplice e comprensibile.
Cos’è la contaminazione dei dati?
Immaginate di prepararvi per un esame importante e, per caso, le domande esatte che affronterete finiscono nei vostri materiali di studio. Il giorno dell’esame, lo superereste brillantemente! Non necessariamente perché avete padroneggiato l’argomento, ma perché avevate già visto le domande. Questo è ciò che accade con la contaminazione dei dati nei modelli di IA. Quando questi modelli vengono addestrati su dataset che includono accidentalmente parti (anche consistenti!) dei benchmark su cui vengono testati, i loro punteggi di performance possono risultare ingannevolmente alti. È come se i nostri modelli di IA avessero avuto un’anteprima del test!
Approfondiamo la questione
Uno studio recente intitolato “Putnam-AXIOM: A Functional and Static Benchmark for Measuring Higher Level Mathematical Reasoning” ha messo in luce proprio questo problema. I ricercatori hanno introdotto il benchmark Putnam-AXIOM, composto da 236 problemi matematici tratti dal William Lowell Putnam Mathematical Competition, completi di soluzioni passo dopo passo. Per affrontare la potenziale contaminazione dei dati, hanno anche creato il benchmark Putnam-AXIOM Variation. Modificando elementi come variabili e costanti, hanno generato nuovi problemi altrettanto impegnativi che non si trovano online. Questo approccio aiuta a garantire che, quando i modelli vengono testati, dimostrino realmente le loro capacità di ragionamento, e non solo richiamino risposte già viste durante l’addestramento.
La contaminazione dei dati non è solo un piccolo intoppo; può distorcere seriamente la nostra comprensione di quanto siano effettivamente capaci questi modelli di IA. Se le prestazioni impressionanti di un modello sono dovute alla memorizzazione dei dati di test piuttosto che a un vero ragionamento, potrebbe non funzionare altrettanto bene in applicazioni reali dove i problemi non sono identici a quelli del suo training. Essendo consapevoli della contaminazione dei dati e affrontandola, i ricercatori possono sviluppare benchmark più accurati, portando a modelli di IA che comprendono e ragionano realmente sui problemi.
Conclusioni
Man mano che l’IA continua a evolversi e a integrarsi in vari aspetti delle nostre vite, garantire l’integrità dei suoi processi di sviluppo e valutazione è fondamentale. Studi come quello su Putnam-AXIOM svolgono un ruolo importante nell’evidenziare sfide come la contaminazione dei dati e nell’aprire la strada a sistemi di IA più robusti e affidabili. Quindi, la prossima volta che sentite parlare di un modello di IA che ottiene risultati straordinari, ricordate l’importanza di dati puliti e non contaminati nel rendere quei risultati veramente significativi.
Immagina un mondo in cui la diagnosi di malattie potenzialmente letali sia rapida e precisa, in cui ogni trattamento contro il cancro sia personalizzato in modo specifico per l’individuo e in cui il potere dei dati e dell’intelligenza artificiale (AI) rivoluziona la cura, la ricerca e la collaborazione. Questo non è un sogno lontano ma una realtà già pronta. Nonostante gli ostacoli normativi e culturali, il potenziale dell’intelligenza artificiale nel settore sanitario è immenso, e in nessun ambito questo è più importante che nella lotta contro il cancro.
La Giornata mondiale contro il cancro (Link) ci ricorda solennemente il prezzo che questa malattia impone non solo alle persone diagnosticate, ma anche ai loro cari e alle comunità. È un giorno in cui la nostra determinazione a lottare contro il cancro viene messa alla prova e allo stesso tempo rafforzata. Inserendo l’intelligenza artificiale nella realtà dell’oncologia, possiamo accendere la speranza, non solo combattendo il cancro ma superandolo strategicamente.
Tre anni fa, abbiamo contribuito a creare l’Healthcare Data Innovation Council (HDIC) rispondendo all’urgente necessità di supportare la trasformazione dell’assistenza sanitaria sfruttando l’enorme potenziale dei dati e dell’intelligenza artificiale. Con l’obiettivo di promuovere miglioramenti sostanziali nella cura dei pazienti, nella ricerca e nella gestione strategica della sanità, il Council è risoluto nell’incoraggiare i cambiamenti culturali, garantendo che i dati e l’intelligenza artificiale siano sfruttati in modo etico e produttivo.
In questa Giornata mondiale contro il cancro, riflettiamo sulla speranza che compare all’orizzonte mentre assistiamo a numerose iniziative che sfruttano la tecnologia e l’intelligenza artificiale come potenti strumenti nel nostro arsenale contro questa malattia. Generando grandi quantità di dati di alta qualità, i ricercatori stanno aprendo nuove possibilità nel trattamento del cancro attraverso tecniche all’avanguardia. L’impatto dell’IA in oncologia è multiforme:
Diagnosi precoce e precisa:
La diagnosi precoce e la precisione nella diagnosi sono cruciali nel trattamento del cancro perché migliorano significativamente le possibilità di successo del trattamento e la sopravvivenza. Quando il cancro viene identificato in una fase precoce, i trattamenti sono spesso meno aggressivi, più mirati e possono essere somministrati prima che la malattia progredisca o crei metastasi in altre parti del corpo. Ciò non solo migliora l’efficacia del trattamento, ma riduce anche il carico fisico ed emotivo sui pazienti. Inoltre, una diagnosi precoce e accurata aiuta a evitare trattamenti eccessivi o insufficienti, portando a una migliore gestione delle risorse sanitarie e riducendo potenzialmente il costo complessivo delle cure.
In questo scenario troviamo progetti come InnerEyeche mirano a democratizzare l’intelligenza artificiale nell’uso dell’imaging medico, facendo già passi da gigante nel Regno Unito, non solo nel settore oncologico. Un altro esempio stimolante è Sybil la soluzione AI del MIT per il cancro del polmone, che vanta un tasso di precisione fino al 94% ed è stata sviluppata analizzando oltre 28.000 scansioni TC per identificare specifici tipi di cancro del polmone.
Medicina personalizzata:
Il trattamento del cancro varia ampiamente perché ogni caso presenta caratteristiche uniche, tra cui il tipo e lo stadio della malattia, la composizione genetica del paziente e lo stato di salute generale, richiedendo approcci terapeutici personalizzati. L’intelligenza artificiale può personalizzare i piani di cura in base ai profili dei singoli pazienti. Ad esempio, l’assistente intelligente di UPMC aiuta i medici a prevedere le risposte individuali all’immunoterapia. Questa tecnologia “Digital Twin” consente ai medici di simulare e adattare i trattamenti, valutando i risultati e gli effetti collaterali prima dell’applicazione effettiva. Chris Carmody, CTO di UPMC, ha dichiarato: “Con questo modello, il team di assistenza sarebbe in grado di modificare i farmaci o altri trattamenti e vedere potenziali risultati o effetti collaterali. Permetterebbe ai medici di testare nuovi piani di trattamento prima di metterli in atto in modo da poter determinare la migliore soluzione da seguire”.
Sviluppo di farmaci e nutrizione:
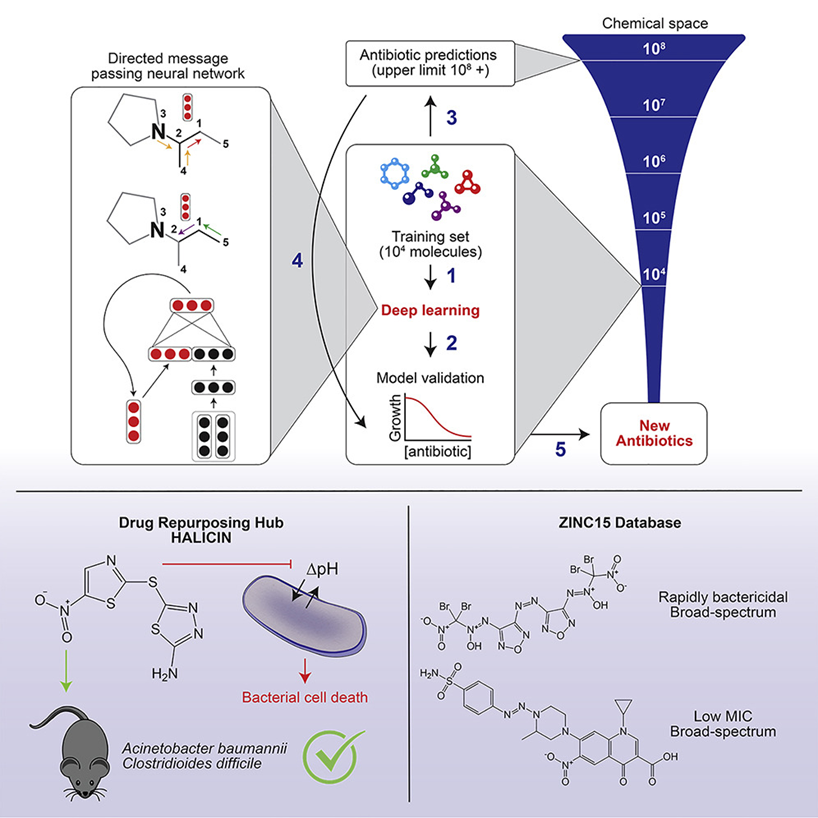
Il ruolo dell’intelligenza artificiale si estende allo sviluppo di farmaci analizzando in modo rapido ed efficace vasti set di dati per identificare potenziali composti e prevederne l’efficacia, riducendo significativamente i tempi e i costi di immissione di nuovi farmaci sul mercato. Molti sono gli esempi ispiratori, questa ricerca pubblicata su Cell, mostra come gli scienziati del MIT hanno creato un sistema che attraverso l’uso del machine learning trova nuovi antibiotici ora che sempre più batteri diventano resistenti a quelli vecchi. Hanno scoperto un nuovo farmaco promettente, l’alicina, che può uccidere un’ampia gamma di batteri nocivi. Analizzando un’enorme libreria di molecole, l’intelligenza artificiale è stata in grado di individuare altri otto potenziali candidati ad antibiotici che non assomigliano per niente a quelli che abbiamo attualmente, dimostrando come ciò potrebbe aiutarci a trovare nuovi farmaci.
Image from: A Deep Learning Approach to Antibiotic Discovery – Jonathan M. Stokes et. al.
Un amico e collega dell’HDIC, il dottor Kirill Veselkov dell’Imperial College di Londra, sta conducendo un’iniziativa stimolante con il suo team chiamato DreamLab. Questa app innovativa sfrutta la potenza di elaborazione inutilizzata degli smartphone per aiutare nella ricerca sul cancro e nella ricerca di nuovi usi dei farmaci esistenti, il tutto mentre il telefono è inattivo, come quando dormi. L’app divide in modo intelligente il complesso compito di analizzare la genetica del cancro in milioni di parti più piccole, rendendolo gestibile dalla potenza collettiva di molti smartphone. Il loro progetto DRUGS mira specificamente a riutilizzare farmaci noti per il trattamento del cancro comprendendo la genetica del cancro. Utilizzano un tipo di intelligenza artificiale all’avanguardia noto come Graph Neural Networks (GNN), che è ottimo nell’analisi di dati complessi, diversi e interconnessi a differenza dell’intelligenza artificiale tradizionale. Le GNN eccellono nella mappatura e nell’apprendimento delle relazioni all’interno di reti complesse, rendendole ideali per affrontare la natura multiforme del cancro e del suo trattamento. Questa tecnologia è molto promettente per svelare le complessità del cancro e favorire lo sviluppo di trattamenti efficaci.
Analisi dei dati complessi:
Il cancro è una malattia complessa che richiede numerosi tipi di test, come analisi genetiche, scansioni mediche o video endoscopici. Questi test generano grandi quantità di dati difficili da correlare e interpretare. L’intelligenza artificiale può essere uno strumento potente per dare un senso a questi dati, sia nell’assistenza clinica che nella ricerca. Ad esempio, la visione artificiale, una tecnica tradizionale di intelligenza artificiale, aiuta a semplificare e analizzare questi dati complessi estraendo informazioni in modo rapido e accurato.
Image from Foundation models for generalist medical artificial intelligence – Michael Moor et.al.
La nuova esplosione dell’intelligenza artificiale generativa, con sempre più grandi modelli linguistici (LLM) in grado di interpretare dati complessi non strutturati, ha portato a un nuovo tipo di modelli di intelligenza artificiale, chiamata Foundation Models, tali modelli possono apprendere da set di dati ampi e diversi senza molta guida umana.
Questi modelli sono versatili, in grado di comprendere e lavorare con vari tipi di dati medici, dalle immagini alle cartelle cliniche elettroniche e altro ancora. Possono fornire approfondimenti dettagliati, come spiegazioni scritte, guida verbale o annotazioni visive, dimostrando una capacità di elaborazione sofisticata dei dati che assomiglia al pensiero umano. I Foundation models hanno un’ampia gamma di potenziali usi nel settore sanitario, ma richiedono competenze tecniche specializzate e set di dati specifici per funzionare in modo efficace. Ma la promessa che offrono è significativa.
Population Health:
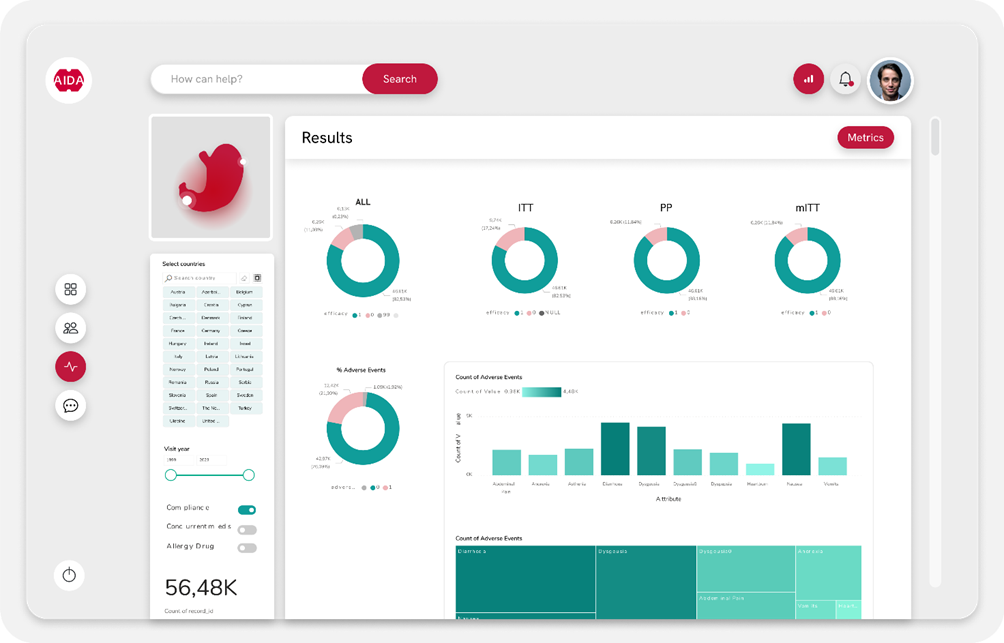
Tra i tanti progressi promettenti offerti dall’intelligenza artificiale nella lotta al cancro, uno dei più efficaci potrebbe riguardare la gestione della salute della popolazione con particolare attenzione alla prevenzione delle malattie. Ad esempio, nel progetto AIDA EU, gli individui con condizioni che aumentano il rischio di cancro, come la presenza di H. Pylori per il cancro gastrico, saranno valutati per stimare il loro rischio effettivo di sviluppare la malattia. Se il progetto avrà successo, quando il rischio è elevato, si potranno adottare misure proattive come l’eradicazione dell’H. Pylori per ridurre significativamente la probabilità di insorgenza del cancro gastrico nella popolazione. Inoltre, per aumentare l’adesione a misure preventive come cambiamenti nella dieta o nell’esercizio fisico, gli strumenti basati sull’intelligenza artificiale possono offrire consigli e approfondimenti su misura. Questi assistenti IA, accessibili al pubblico, saranno preziosi per condividere informazioni e ricerche pertinenti specificamente adatte alla situazione sanitaria di ciascun individuo
Dashboard del progetto AIDA EU
Le opportunità offerte da queste tecnologie emergenti sono vaste, ma per la loro adozione significativa si devono affrontare numerosi ostacoli. Per vincere queste sfide, dobbiamo sostenere un cambiamento culturale verso un’assistenza sanitaria basata sui dati, affrontare le carenze di competenze e stabilire un ricco quadro normativo per promuovere l’accessibilità e la convenienza di queste soluzioni e dell’accesso ai dati.
In conclusione, mentre guardiamo al futuro, alla Giornata mondiale contro il cancro 2025, siamo sull’orlo di una rivoluzione guidata dall’intelligenza artificiale nel settore sanitario. Con iniziative come lo Spazio europeo dei dati sanitari e la legge sull’IA recentemente approvata, speriamo che il mondo renda l’intelligenza artificiale parte integrante della lotta contro il cancro.
La nostra speranza collettiva è che entro il prossimo anno vedremo un impegno ancora più forte nell’impiego dell’intelligenza artificiale nel nostro tentativo di sradicare il cancro una volta per tutte. Continuiamo a spingere oltre i confini dell’innovazione, perché la promessa dell’intelligenza artificiale in oncologia non è solo quella di curare ma di trionfare sul cancro. #CloseTheCareGap
Unisciti a noi per sfruttare la potenza dell’intelligenza artificiale per trasformare la cura del cancro. La tua consapevolezza e il tuo sostegno sono fondamentali per utilizzare queste tecnologie rivoluzionarie per il bene comune. Condividi questo messaggio e attivati per sostenere l’utilizzo dell’intelligenza artificiale nel settore sanitario.
Mentre la pandemia stava scomparendo dalle notizie, un’innovativa startup, Midjourney, ha fatto il suo debutto, sostenendosi autonomamente e affermandosi come un “laboratorio di ricerca indipendente”. Midjourney ha trasformato una visione semplice ma rivoluzionaria in realtà, sviluppando tecnologie esclusive basate sui primi studi dei modelli noti come Diffusion Models. Con un’offerta distintiva, questa startup ha lanciato una piattaforma che democratizza la creazione di immagini sintetiche: chiunque, con un semplice prompt, può accedere al servizio e dar vita a immagini generate artificialmente con facilità e immediatezza
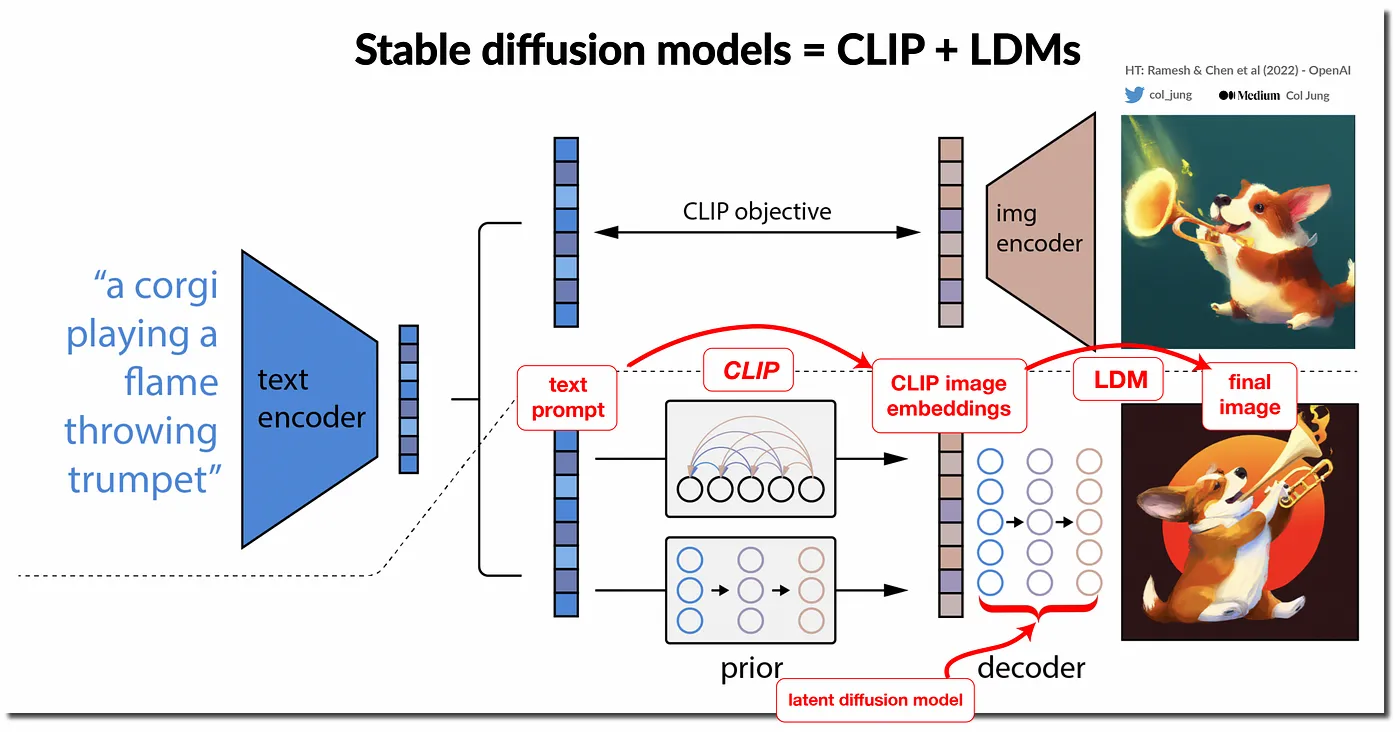
I modelli di diffusione rappresentano un’avanguardia nell’ambito dei modelli generativi, sfruttando processi elaborati per creare immagini sintetiche partendo da semplici descrizioni testuali. Questi modelli iniziano con una immagine casuale e attraverso una serie di passaggi progressivi, applicano modifiche controllate e reversibili. Ogni trasformazione si avvicina sempre di più all’immagine desiderata, delineata dal testo del prompt. Questo avviene sotto la guida di architetture di reti neurali sofisticate, che hanno il compito di enfatizzare gli aspetti rilevanti dell’immagine finale, eliminando contemporaneamente qualsiasi distorsione o “rumore”.
Il fulcro di questi modelli sono le reti neurali di tipo transformer, che condividono la stessa architettura dei Large Language Models (LLM). Queste reti non solo identificano le caratteristiche pertinenti al prompt, ma lavorano in sinergia con i Latent Diffusion Models (LDM). Gli LDM affinano ulteriormente il processo, assicurando che l’immagine risultante non sia solo fedele alla descrizione, ma anche di alta qualità, con coerenza visiva e dettagli raffinati. Insieme, questi due tipi di modelli definiscono lo stato dell’arte nella generazione di immagini sintetiche, spianando la strada per creazioni sempre più realistiche e dettagliate, nate dall’intreccio tra artefatti visivi e linguaggio naturale
Schema di funzionamento dei modelli a diffusione – Ramesh & Chen et. al (2022)
Alcuni dei modelli di generazione di immagini più avanzati, come Stable Diffusion e Dall-E 3, sono accessibili gratuitamente al pubblico, sebbene richiedano una certa competenza tecnica. In risposta a questa esigenza, David Holz, già noto per aver co-fondato Leap Motion, ha intrapreso l’iniziativa di sviluppare e offrire i suoi modelli di intelligenza artificiale basandosi su un sistema di abbonamento. Questi modelli sono caratterizzati dalla facilità di utilizzo, grazie all’adozione di una piattaforma intuitiva che combina Discord con una WebApp essenziale.
La sua proposta si distingue per la semplicità e la velocità: la prima versione è stata rilasciata nel febbraio 2022, segnando un ciclo di miglioramenti costanti ogni due mesi. Questo ritmo di aggiornamento ha iniziato a rallentare nel 2023, con il rilascio della versione 5 a marzo e, di recente, la versione 6 in alpha il 21 dicembre.
Nonostante la sua popolarità, Midjourney impone un rigido sistema di moderazione che limita la creazione di contenuti: il blocco di parole chiave specifiche impedisce la generazione di immagini erotiche o violente e estende il divieto a termini legati alla religione o a figure di spicco mondiale. Questa politica di moderazione, tuttavia, non ha frenato l’espansione della base utenti, che ha raggiunto una cifra impressionante di 17 milioni di individui attivi sulla piattaforma.
David Holz, in un’intervista, ha rivelato che Midjourney ha iniziato a generare profitto già ad agosto 2022. Questo dimostra l’impressionante redditività della startup, che non ha avuto bisogno di finanziamenti esterni, bensì ha capitalizzato su un vasto mercato inesploso utilizzando AI avanzate, riuscendo a scalare rapidamente nel settore.
Da quando ha introdotto abbonamenti a pagamento nel dicembre 2022, Midjourney ha registrato introiti per circa 250 milioni di dollari, e la sua base di utenti cresce quotidianamente di 23.000 persone, con l’80% che opta per un abbonamento settimanale fin dai primi giorni di utilizzo.
Con appena 100 dipendenti, Midjourney sta rivoluzionando il mondo dell’arte, del design e dell’intrattenimento. Senza piani astrusi o ingenti investimenti, si dedica al continuo perfezionamento dei suoi modelli, rendendoli disponibili a tutti. Questo caso è emblematico di come l’intelligenza artificiale possa generare notevoli guadagni per chi sa sfruttarne rapidamente le applicazioni pratiche e i casi d’uso.
Mentre l’anno si avvicina al suo epilogo, invitiamo Midjourney a tracciare il nostro augurio per l’anno nuovo, attingendo alla bellezza del mare di Genova per un saluto che sia porta di speranza. Possa il 2023 aprirci gli occhi sull’impatto trasformativo dell’intelligenza artificiale, che promette di arricchire la società e guidarci nell’affrontare le sfide globali. Con fiducia e rinnovata consapevolezza, accogliamo l’anno nuovo, pronti a navigare verso orizzonti di progresso e benessere.
In questo inizio d’anno, diverse realtà stanno proponendo scenari sulle tecnologie digitali emergenti che avranno impatto nel prossimo futuro.
E’ sempre interessante avere una percezione di cosa viene raccontato e di come questi scenari siano popolati da macro-trend che definiscono la maturazione di un filone tecnologico, ed il suo adattamento a soluzioni più pratiche.
Tra queste analisi una interessante è quella di Gartner dell’Impact Radar (ne trovate un estratto QUI)
In questo orientamento vediamo diverse tecnologie emergenti, e la loro rappresentazione per impatto, tempo necessario per la maturazione sul mercato, e raggruppamento in macro ambiti.
Uno dei primi temi che emerge è come Dati ed Intelligenza artificiale siano elementi centrali. Questo sia in ambiti di Rivoluzione della Produttività (Dati sintetici, AI Generativa, Self-supervised Learning, Edge AI o AIASE, dove è tutto concentrato su AI e dati) che in ambito di Smart World (IoT, Assistenti virtuali avanzati o Smart Spaces) dove l’AI viene invece applicato concretamente ed i dati raccolti, ma anche in ambito di abilitatori critici (Graph Technologies o AI generated composite applications).
Sono molto poche le tecnologie emergenti che non utilizzano, sono correlate, o sono aree specifiche di Intelligenza artificiale legata ai dati.
Alcuni ambiti sono già maturi (e necessari) come le piattaforme Low Code (LCAP) per accelerare l’implementazioni di applicazioni distribuite in scenari dove la carenza di competenze di programmazione è ormai critica o le autenticazioni Passwordless, per risolvere il principale fattore di vulnerabilità legato alle credenziali utente.
L’AI ed i dati sembrerebbero poco rappresentati nello scenario che, forse, subirà un’accelerazione nel prossimo futuro: (Sicurezza onnipresente e trasparente), anche se in questo report non vengono identificate tecnologie e modalità emergenti come l’UEBA (User and Entity Behavior Analytics) o l’XDR (Extended detection and response), tecnologie che si fondano su modalità di analisi avanzate e machine learning.
Un’altra cosa importante che emerge da questo rapporto è come, nonostante alcune evoluzioni recenti che potrebbero rendere le architetture più efficienti dal punto di vista energetico (Proof-of-stake), sia totalmente fuori dai radar la tecnologia Blockchain, da molti paragonata, per impatto futuro atteso, all’Intelligenza artificiale.
Dal punto di vista strategico queste valutazioni sono molto interessanti, sia per valutare investimenti e sviluppo di competenze, che per comprendere quali percorsi di sviluppo pianificare per adottare tecnologie che possano portare impatti in prodotti ed ambienti digitali.
Come raccomandazioni penso che le opportunità che emergono da questo rapporto si possano trovare in questi ambiti:
Investimento su esperienze utenti più personalizzate che possano facilitare l’adozione della tecnologia in più scenari, utilizzando sia gli assistenti virtuali evoluti che le interfacce multimodali
Valutare l’adozione progressiva di tecnologie come lo sviluppo software AI-augmented (AIASE) che consentirà di ridurre i costi di realizzazione delle applicazioni aumentandone la qualità media, aspetto di grande valore in un contesto globale che vede la domanda di produzione software molto superiore alla capacità effettiva di produzione.
Implementare progressivamente tecnologie di AI generativa (e dati sintetici), un’ambito di applicazione di enorme potenziale in molti ambiti (personalmente avrei inserito l’AI Generativa tra gli abilitatori critici)
Adottare rapidamente tecnologie di autenticazione con la modalità Passwordless (Adozione semplice ma necessità di sviluppo culturale interno ed esterno) e di piattaforme Low Code nel portafoglio applicativo.
E’ ormai noto come il Machine Learning, il vero motore della svolta verso l’attuale Intelligenza Artificiale, sia particolarmente esigente dal punto di vista computazionale. I chip (CPU) tradizionali non sono particolarmente efficienti nello svolgere questo tipo di calcoli, e consumano troppa energia. Per questo, al momento, vengono utilizzati prevalentemente i chip per i calcoli grafici (Graphical Processing Unit o GPU).
Questa esigenza ha portato aziende come NVIDIA a far parte dei leader in questo settore, con spinte molto grandi alla loro capitalizzazione ed ai loro risultati. NVIDIA per questo, negli anni ha fatto virare completamente la sua GPU Conference verso l’AI, condividendo risultati, scenari di utilizzo e dei video di apertura meravigliosi! Fantastica la loro colonna sonora prodotta da AIVA Technologies e suonata da un’orchestra umana, davvero molto emozionanti (QUI trovate il video della GTC del 2019).
Il punto è che, comunque, l’addestramento delle architetture di ML sempre più sofisticate che si stanno realizzando, senza considerare utilizzi anche più stimolanti come le Generative Adversarial Network o GAN o il Deep Reinforcement Learning, richiede quantità di energia elettrica notevoli anche con le GPU. Per questo uno dei temi sui quali si sta lavorando è la creazione di architetture specifiche per l’addestramento e di chip specifici per task di AI (Huawei ad esempio ha nella sua offerta di AI una piattaforma end-to-end dai chip ai framework per la scrittura degli algoritmi).
In questo scenario Google ha realizzato la piattaforma open source per il machine learning più diffusa al mondo al momento: Tensorflow. Questa piattaforma sta cominciando a comprendere modalità di utilizzo che si mappano specificamente sull’hardware sottostante, con una predilezione per due tipologie di chip ASIC e FPGA. Queste due famiglie di chip comprendono tutti i chip che, programmabili (FPGA) o specifici (ASIC), sono stati pensati per applicazioni specifiche come ad esempio il Machine Learning.
Ora, progettare un chip è un’operazione lunga e laboriosa, paragonabile ad un tetris multidimensionale, dove è necessario pianificare con attenzione il posizionamento di migliaia di componenti, su più strati, in un’area confinata e con risorse limitate. Bisogna quindi analizzare ogni pianificazione effettuata per ottimizzare il numero di connessioni e massimizzare quindi l’efficienza (e quindi i consumi) del piano appena realizzato. I software di electronic design automation (EDA) che analizzano le pianificazioni e simulano le performance, possono richiedere poi anche 30 ore per ogni strato per produrre i report di efficienza delle pianificazioni realizzate.
Questo approccio costoso e lungo fa si che ogni progetto di chip duri diversi anni, prima che vengano testati nuovi approcci e nuove pianificazioni, questo fino quantomeno ad oggi.
Due ricercatrici di Google: Anna Goldie ed Azalia Mirhoseini, hanno pubblicato un paper intitolato: Placement Optimization with Deep Reinforcement Learning che promette un futuro molto diverso e per certi versi intrigante. Il paper può essere scarivato QUI da arxiv.
Nel paper analizzano come, utilizzando apprendimento per rinforzo (Reinforcement learning), riescano a simulare diverse centinaia di pianificazioni differenti ed a scegliere, in maniera gradualmente sempre più rapida, quelle più efficienti.
La validazione effettuata con i software, al termine del processo ha portato a rilevare pianificazioni più efficienti di quelle realizzate dagli ingegneri umani, ed anche a conoscenze e scoperte per l’uomo, un po’ come appreso nel percorso reso famoso da AlphaGO.
Siamo ovviamente molto lontani da macchine che progettano macchine più efficienti, ma è un primo passo, molto interessante, dove peraltro si utilizza una tecnologia promettente come il Reinforcement Learning che non richiede alcun tipo di dato storico di qualità esistente, e che, anzi, genera conoscenza dall’esperienza, conoscenza che può essere messa a disposizione di tutti.
In giapponese la rappresentazione del concetto di “crisi” viene effettuato tramite due ideogrammi che, separatamente rappresentano pericolo ed opportunità.
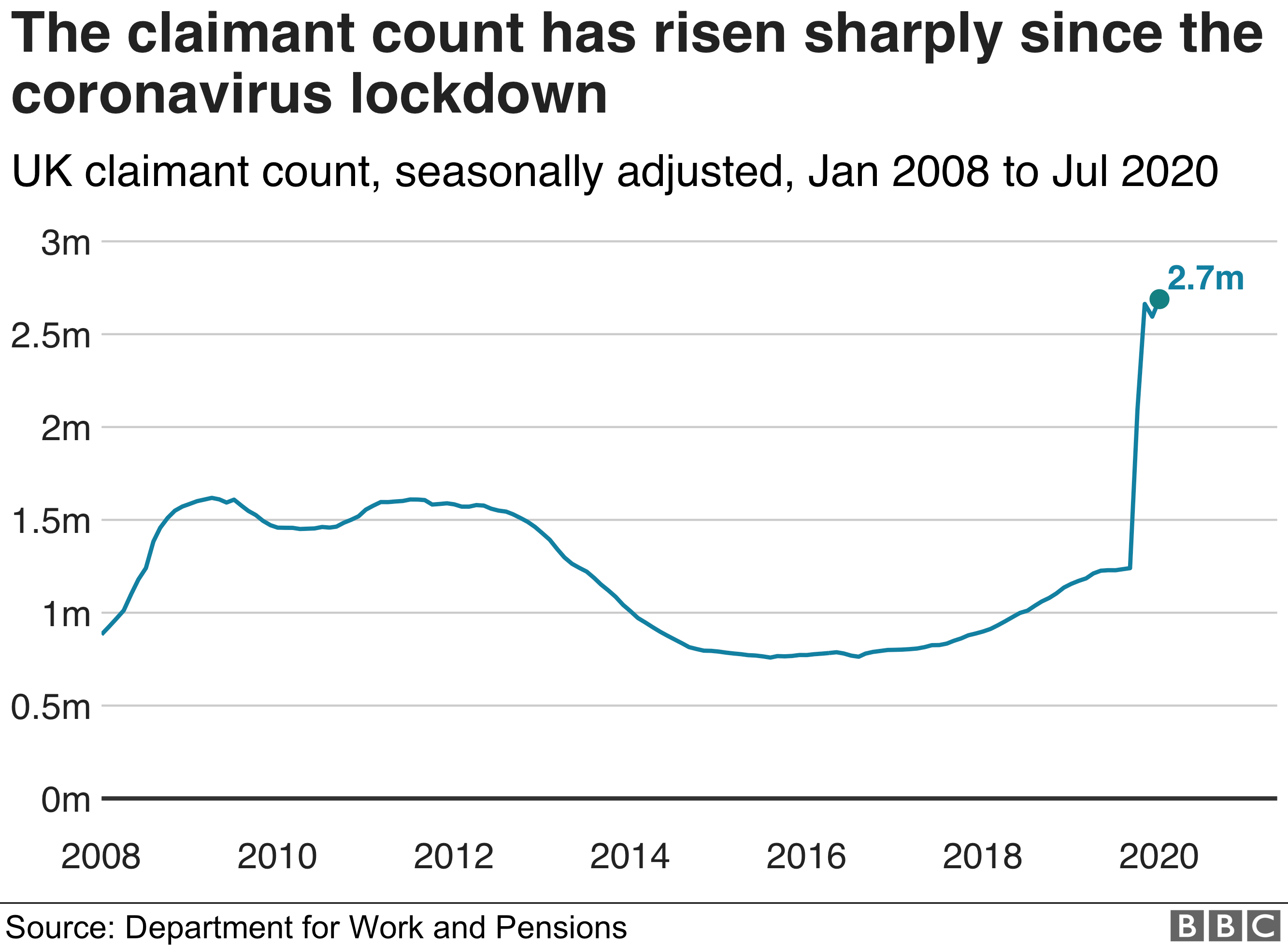
Negli Stati Uniti il lockdown (peraltro limitato) ha causato la perdita di tutta l’occupazione conquistata dall’economia negli ultimi anni, con picchi elevatissimi. Solo nell’ultimo periodo la ripresa ha riportato la disoccupazione all’11.1% contro il 14.7% che era ad aprile. Se si considera che nel 2019 il tasso medio era del 3,5% si comprende la portata della crisi economica.
In Europa le moratorie sui licenziamenti e il sostegno finanziario offerto dalla UE e dai singoli governi ha mantenuto la situazione per ora limitata, anche se alcune nazioni che non hanno più i benefici dell’ombrello europeo stanno già pagando dei dazi significativi
In UK il numero dei richiedenti un sussidio di disoccupazione è salito da poco più di un milione di richiedenti, agli attuali 2,7 milioni. La pandemia è stata sicuramente (e rischia di essere ancora) nefasta per gli anziani, che avevano tassi di mortalità molto più rilevanti dei giovani, ma il prezzo economico, in termini di disoccupazione, lo pagano invece i più giovani, che rischiano di rimanere bloccati da un’economia che sarà colpita duramente e da modalità di consumo e di comportamento che sono cambiate e cambieranno ancora.
In questo scenario di crisi, il pericolo di trovarsi senza lavoro è quindi serio, ma gli spazi di opportunità sono molto interessanti:
L’economia digitale sta crescendo a ritmi sostenuti, e c’è la necessità in Europa di rispondere ad una crescente domanda di competenze nel mondo IT e dell’analisi dei dati che già oggi ha un buco di diverse centinaia di migliaia di competenze.
In questo scenario molto interessante la proposta emergente di Google che sta creando tre percorsi di carriera davvero molto promettenti:
I tre percorsi che propone sono per tre profili tutti molto ricercati: Data Analyst, Project Manager e UX designers. Tutti i percorsi saranno ospitati su Coursera e la durata del corso sarà di circa 6 mesi. Il costo per accedere a questi percorsi sarà di 49$ al mese.
Google afferma nel lancio di questa iniziativa che chi completerà questi percorsi sarà valutato nei suoi processi di selezione come se avesse seguito un quadriennale sul tema specifico.
Nella pagina di introduzione inseriscono anche le retribuzioni attese (in USA) per ogni profilo, con una descrizione molto sintetica del contesto.
L’iniziativa mi sembra nobile e promettente e penso che possa offrire spunti anche a tanti ragazzi italiani, laureati e non!
Brava Google, un bel lavoro, sarebbe bello avere più percorsi di questo tipo anche più EU tailored da parte di tutti i big technology vendors!
Una decina di giorni fa, entrando nella 4 settimana di lockdown, avevamo visto come le misure di distanziamento sociale e di riduzione del movimento tra comuni diversi stavano avendo un effetto nella riduzione della progressione epidemica.
Avevamo anche rilevato come, d’altra parte, ci fossero delle significative variazioni nelle misure: Sia nella percentuale dei positivi rilevati ai tamponi che nell’apparente variazione dei decessi rapportati ai casi scoperti tra regione e regione.
Questo portava a percezioni distorte e anche a suggestive ipotesi che sono emerse nei giorni recenti (il 5G causa del COVID, sob!). In realtà pochi giorni dopo il dipartimento che segue le malattie infettive dell’Imperial College rilasciava uno studio dove evidenziava come la quantità di undiscovered presente in ciascuna nazione fosse molto significativa (come già raccontato qualche settimana fa su questo stesso Blog) e questo poneva dei dubbi sulle nostre capacità di misura ed anche sull’effettiva riduzione del contagio.
Fonte: Estimating the number of infections and the impact of non-pharmaceutical interventions on COVID-19 in 11 European countries
Come accade ultimamente non solo pubblicavano lo studio e le fonti, così da poterlo far rivedere dai peer, ma anche i sorgenti su GitHub: QUI (Sono in formato RStudio, strumento di analisi statistica gratuitamente scaricabile).
L’idea di base che hanno seguito è simile a quanto avevamo condiviso: La letalità del COVID-19 è variabile per classe di età (ed anche un po’ per sesso, andando a colpire in misura maggiore i maschi) e si ritiene che non vari per etnia, quindi, partendo dalla letalità analizzata in Cina, si può calcolare l’infection fatality ratio(IFR) di una nazione o di una Regione adattando la demografia relativa.
Fonte: Estimates of the severity of coronavirus disease 2019: a model-based analysis. Verity et.al
Guardando questi numeri (Importante l’ultima colonna: Infection Fatality Ratio), si nota come il COVID-19 sia particolarmente letale per gli over-80 (7,8% medio) mentre è scarsamente letale per i giovanissimi e, più generalmente, meno letale per gli under-60 (0,145%medio).
Per fortuna tutti i dati anche demografici sono a disposizione e quindi andando a rilevare i dati specifici si può creare un indice di letalità medio per ogni stato o regione.
Veniamo ora a noi: Sappiamo purtroppo che la Liguria è una regione con una distribuzione anagrafica molto sbilanciata verso le età più anziane, ed infatti, andando ad adattare l’indice di letalità per la Regione scopriamo che ha un indice medio di letalità che è il più alto d’Italia: 1,68
Infection fatality ratio in Italia – elaborazione su dati I.stat
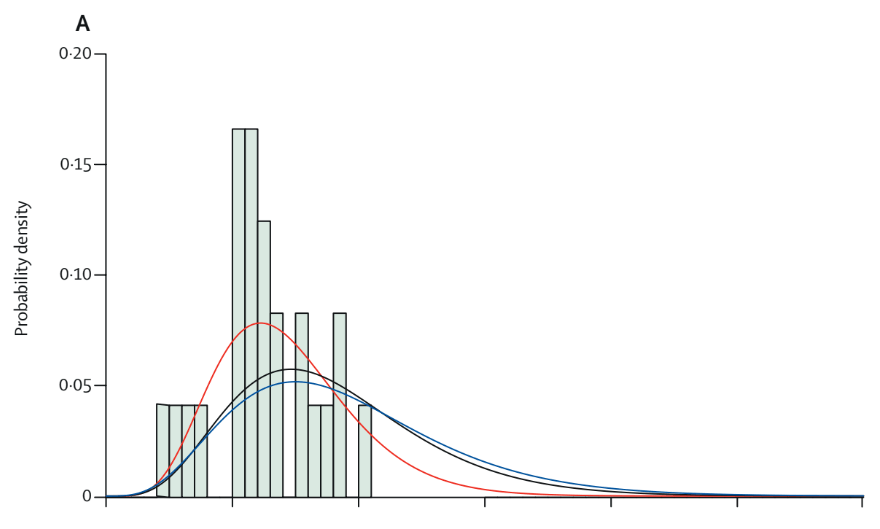
Conoscendo l’IFR adattato alla regione, si può calcolare a ritroso il numero reale di infetti, andando a stimare anche quanti sono infetti ed asintomatici (o paucisintomatici) o semplicemente non rilevati. Questo calcolo, che segue lo stesso principio utilizzato da Imperial College per il suo modello che stima i casi reali, ci consente però di stimarli indietro nel tempo, visto che intercorre un certo tempo sia dall’infezione che all’insorgenza dei sintomi, che dall’insorgenza dei sintomi al decesso (nel caso di esito infausto). Siamo ancora nelle fasi iniziali di studio di questa epidemia, e potrebbe essere che i tempi di ritardo stimati siano ancora corti, possiamo rilevare dallo studio di Verity et. al, la distribuzione di probabilità nei ritardi:
Onset to Death distribuzione di probabilità – Estimates of the severity of coronavirus disease 2019: a model-based analysis – Verity et. alia
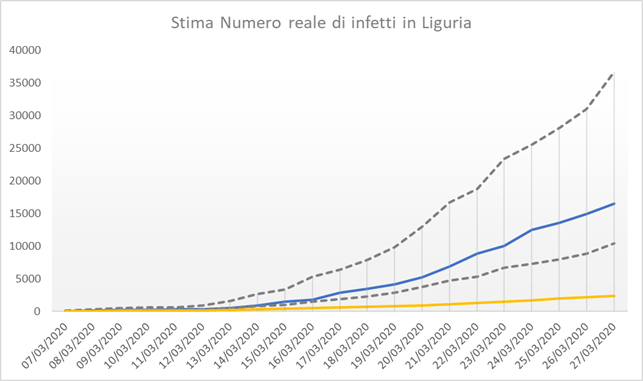
Utilizzando quindi un ritardo di 12 giorni avremo una distribuzione della stima degli infetti reali non corretta in partenza ed in chiusura del fenomeno, ma coerente durante il fenomeno. Da qui possiamo quindi calcolare quanti infetti veri (true) avevamo 12 giorni prima di ciascun decesso (sapendo che, in Liguria, i decessi sono l’1.68% degli infetti presenti 12 giorni prima):
Stima numero reali di infetti da IFR – Elaborazione su dati DPC
La retta arancione è quella dei casi rilevati, quella blu la media degli infetti reali stimati, con le sue bande di confidenza (i.c. 95%). Come si vede siamo molto distanti da rilevare una percentuale significativa dei casi anche se, per quanto il numero di test cresca non in proporzione alla crescita della diffusione, la maggior consapevolezza dell’epidemia porta progressivamente ad una riduzione degli undiscovered, anche di pochi punti percentuali:
Stima % undiscovered in Liguria e proiezione futura – Elaborazione
Inizialmente, quindi (prima dei primi decessi), l’epidemia si diffondeva, la poca consapevolezza ed i pochi test portavano a molti contagiati che uscivano dal controllo, mentre progressivamente (nel quadrato si evidenzia una stima della progressione realizzata) si converge verso i valori che si sono rilevati ex-post, anche in Cina (82%-90% di undiscovered, con una mediana 86%). Alcune regioni italiane hanno percentuali di undiscovered più basse (e quindi rilevano dati più coerenti), altre più alte, probabilmente per la maggiore diffusione del contagio in quelle aree.
Avendo questo parametro si possono provare a definire previsioni e tracciare curve di uscita, per quanto sempre complesso su un sistema dinamico e con ritardi come quello che si sta analizzando, dalle valutazioni fatte, però, risultano evidenti una serie di aspetti:
La quantità dei contagi fuori dai radar è molto significativa in Liguria (come in tutte le Regioni italiane ed in Cina prima)
Per quanto più grande il numero dei contagiati, anche guariti è molto basso se rapportato alla popolazione complessiva
La decrescita degli infetti infettivi appare molto lenta e non consente di individuare un termine dell’emergenza a breve.
Monitoreremo quindi gli andamenti per valutare se i dati futuri portino accelerazioni, anche se, dopo aver rilevato questa decrescita apparentemente lenta nelle curve, ho verificato come mai sembrava che la Cina, tramite gli interventi non farmacologici (NPI), aveva portato una riduzione quasi a zero dei suoi contagi molto più rapidamente, ed ho trovato che la progressione del contagio, in Cina, ha avuto questo andamento:
Andamento COVID-19 in Cina nei mesi di Gennaio e Febbraio – fonte Evolving Epidemiology and Impact of Non-pharmaceutical Interventions on the Outbreak of Coronavirus Disease 2019 in Wuhan, China
Come si nota dopo un primo “abbattimento” della curva progressiva, che aveva un andamento esponenziale nei primi momenti, hanno stabilizzato la progressione, rendendola quasi endemica. Dopo una decina di giorni, infine, hanno portato una riduzione del contagio molto più rapida di quella che stiamo vivendo e osservando noi in questi giorni in Italia e nella nostra Regione (Rt=0,32).
Dallo studio, così come dal report del WHO, emerge infatti che da inizio febbraio in Cina abbiamo cominciato a rendere più efficaci e frequenti i test, tracciarei contatti dei positivi e dei sospetti, e isolare sia i positivi che i sospetti. La cosa sorprendente è che questo approccio (test, trace and treat) è considerato, sempre dal World Health Organization (WHO) la spina dorsale (Backbone) della risposta al contagio da COVID-19. Speriamo quindi di vedere valutate presto misure come queste.
Conclusioni (per il momento!) – Sappiamo che c’è un gran numero di contagiati (comunque infettivi) che non viene scoperto – L’italia, essendo una nazione con un ottimo sistema sanitario ed una buona qualità della vita è la nazione in Europa con l’età media più alta, ed avrà quindi più decessi per COVID a parità di contagi delle altre nazioni (IFR). – Le attuali curve di uscita, per quanto ancora incerte, non suggeriscono una rapida eradicazione del contagio e richiedono quindi di mantenere le misure di soppressione (lockdown, limitazioni al movimento) per un periodo di tempo non breve – Anche in Cina le prime risposte hanno portato una riduzione ma non definitiva, che ha richiesto altre misure, che sono poi state riportate dal WHO (intervista del 18 marzo scorso) come spina dorsale della risposta. Apparentemente queste misure non sono state ancora intraprese da alcuna nazione Europea.
Articoli e fonti consultate: – Real estimates of mortality following COVID-19 infection (2020) – Evolving Epidemiology and Impact of Non-pharmaceutical Interventions on the Outbreak of Coronavirus Disease 2019 in Wuhan, China (2020) – Wang et. al. – Estimating the number of infections and the impact of non-pharmaceutical interventions on COVID-19 in 11 European countries (2020) – Flaxman et. al – Estimates of the severity of coronavirus disease 2019: a model-based analysis (2020) – Verity et al.
Stiamo entrando, in Italia, ormai nella 4 settimana di lockdown. Questo a seguito del decreto del 9 marzo, nel quale l’intero territorio nazionale è stato dichiarato zona rossa.
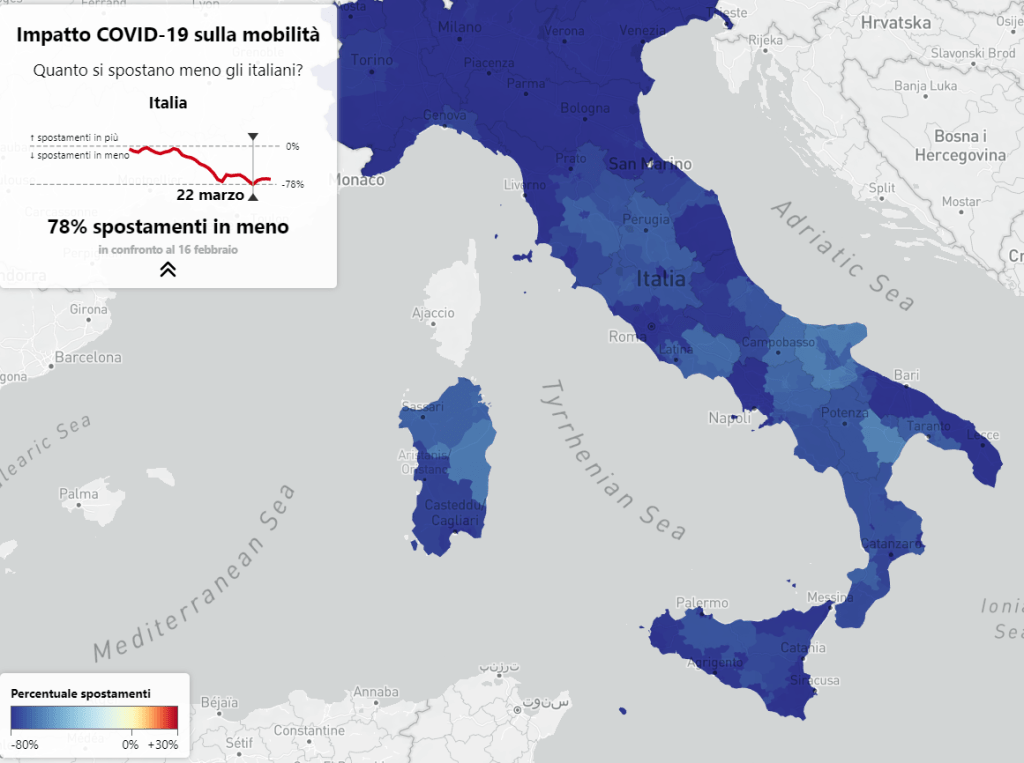
Oltre al lockdown (inteso come chiusura di attività commerciali, ludico-ricreative e scolastiche), è stata definita anche una misura di restrizione al movimento fra comuni diversi. Queste misure hanno ridotto enormemente la mobilità nella nostra nazione, ed i risultati sono stati evidenti e sostanziali, come mostrato molto bene, oggi, in un articolo dotato di mappe interattive di Repubblica (bravi!).
Mobilità in Italia durante il mese di marzo – Fonte Repubblica
Gli Italiani (da Nord a Sud), sono stati disciplinati ed attenti, arrivando ad una riduzione di movimento dell’81% durante domenica 15 (i due giorni di maggiore riduzione sono stati il 15 ed il 22 di marzo, due domeniche), ed una riduzione media di circa il 64% durante i giorni lavorativi.
La curva di riduzione del movimento è stata progressiva con l’estendersi dei decreti, salvo stabilizzarsi negli ultimi giorni: dal 14 marzo la tendenza alla riduzione del movimento è stabile scendendo solo durante i week-end.
Dobbiamo a questo punto domandarci: Possiamo definire Quando potranno terminare le misure restrittive?
Sempre partendo dalle analisi già fatte e sui modelli realizzati per la progressione nella Regione Liguria, vediamo come i numeri sono evoluti: Sappiamo molto di più sia sui tempi di incubazione, del COVID, che sulla durata del periodo infettivo, gli studi sul tema sono ora molti ed offrono indicazioni consistenti: Ci sono 14 studi significativi che affrontano il tema del periodo di incubazione, e si osserva che il 95% delle osservazioni ricade tra i 2.1 giorni e gli 11 giorni, con una mediana a 5.2 giorni.
A 5,2 giorni di distanza vedremo quindi circa il 70% degli effetti, mentre a 7 giorni potremo rilevare il 96% degli effetti (ci rimarrà fuori solo una piccola coda di incubazioni lunghe): Oggi possiamo quindi affermare che stiamo vedendo nei numeri l’interezza degli effetti delle misure restrittive e per questo possiamo cominciare a proiettare delle nuove curve che ci diano indicazioni su come sta progredendo l’epidemia e formulare ipotesi sulla sua evoluzione.
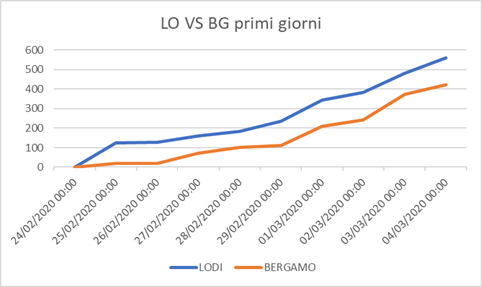
Gli effetti sono stati molto significativi, e la tempestività delle misure porta a differenze enormi negli esiti. Interessante rilevare gli impatti della scelta di non includere la Provincia di Bergamo nella prima zona rossa: Come si può notare dalle progressioni la provincia di Lodi e quella di Bergamo avevano nei primi giorni una progressione molto simile:
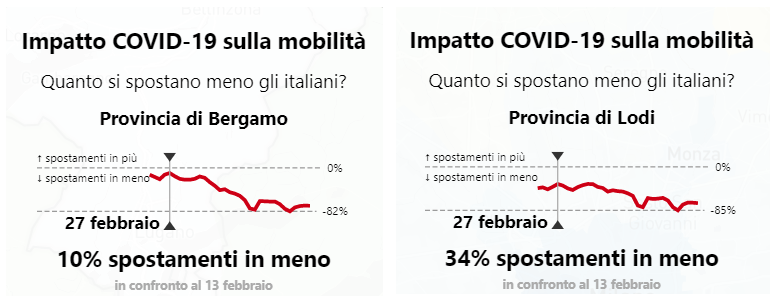
Per quanto simili le due progressioni mostravano già una convergenza, con la progressione di Bergamo che appare più rapida. Ora, se andiamo a 7 giorni prima (per il ritardo introdotto dal periodo di incubazione) il 27 febbraio vediamo come era la situazione della riduzione di mobilità:
Raffronto riduzione mobilità da analisi Repubblica su celle telefoniche
A Lodi gli spostamenti erano già molto ridotti: -34%, la metà della media attuale, mentre a Bergamo si rileva una riduzione ma non ancora consistente (Sarebbe arrivata al 34% in meno 1 settimana dopo, il 7 di marzo). Questa differenza nei tempi di applicazione delle misure porta a risultati nella progressione e nel numero dei contagi molto diversi:
Confronto progressione Lodi e Bergamo dal 5 al 23 di marzo.
Questo ci porta a due considerazioni importanti: Anche ritardi minimi portano a progressi della curva molto importanti (come si è visto per Bergamo e come, temo, si vedrà per tante altre nazioni europee che pur avendo lo scenario italiano come riferimento, sono state meno reattive nel prendere misure) e anche spostamenti più contenuti, come nel caso della provincia di Lodi (-34% può significare, in astratto che 1 persona su 3 non si muovesse), possono portare a riduzioni sostanziali nel progresso dell’epidemia.
Veniamo ora alla Liguria, noi liguri, come sempre, siamo stati rispettosi ed attenti, ed abbiamo avuto riduzioni di mobilità in linea con quanto accaduto nel Nord Italia:
Analisi Mobilità Liguria con andamento da elaborazione Repubblica
Ed oggi, dove vediamo già l’effetto di tutte le misure, anche valutando opportunamente la distribuzione dei tempi di incubazione, vediamo una riduzione significativa della curva, avvenuta in due momenti differenti:
Il 10 marzo, come riportato anche nell’articolo precedente, considerando che non avremmo ancora visto un impatto significativo delle misure per il ritardo causato dal tempo di incubazione della malattia, avevo fatto una previsione dell’andamento, andando ad interpolare la curva, che è risultata coerente fino al 15 marzo momento nel quale, progressivamente, abbiamo assistito ad una riduzione della crescita (la riduzione di mobilità è avvenuta con l’entrata in vigore del decreto del 12 marzo).
Il 19 marzo ho interpolato nuovamente la progressione con i dati aggiorni, ed è risultata coerente nuovamente fino al 22 di marzo, assistendo anche qui ad una leggera flessione, questa meno motivata dagli ulteriori decreti restrittivi che, come si nota, non hanno variato sostanzialmente la mobilità.
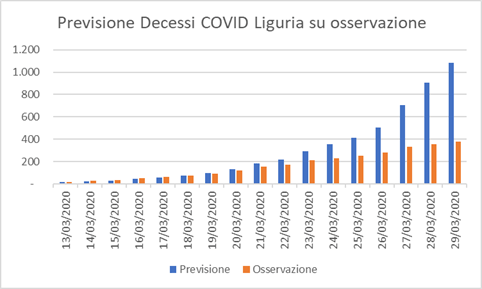
E’ possibile, e penso che sia anche di valore per tutti, sulla base di queste minori incidenze, calcolare quanti decessi in meno abbiamo avuto in una regione particolarmente fragile per questo fenomeno epidemico, vista l’età media più elevata d’Italia:
Questa proiezione, è naturalmente solo stimata ed è stata calcolata andando a proiettare il reale numero di infezioni senza attuare alcuna misura restrittiva, e applicandogli il tasso di letalità per caso (Case fatality ratio o CFR) giornaliero osservato.
Quindi l’impatto socio economico che stiamo vedendo e vivendo ogni giorno, solo in Liguria, ha risparmiato più di 700 vite! senza calcolare il maggiore stress che il sistema sanitario avrebbe avuto e che avrebbe potuto causare più vittime, non solo legate alle patologie portate dal virus.
Andando però a calcolare questa proiezione, si nota come lo stress del sistema stia portando a sottostimare gradualmente sempre di più i casi reali. Questo lo si può notare da diversi indicatori, il primo è proprio il CFR che sappiamo essere stato in Cina intorno a 4%, o in Corea, addirittura sotto l’1%. Questo parametro si ottiene dividendo il numero di decessi per il numero di casi scoperti (e testati). L’andamento di questo parametro, nel corso dei giorni, in Liguria è stato questo:
Quest’analisi ci mostra come l’andamento di questo parametro è stato progressivamente in aumento (a parte gli aggiustamenti iniziali), fino ad arrivare ad una letalità del 12,7%, valore altissimo anche adeguando demograficamente la letalità sulle osservazioni precedenti (andando quindi ad aumentarla per la maggiore età media Ligure). Per correlare questo parametro possiamo vedere come la percentuale di tamponi positivi sia salita in maniera analoga e correlata:
Quindi, nello stesso periodo, siamo passati da rilevare un 15% di positivi (e conseguentemente la letalità era del 4%) ad un 35% di positivi (Con la letalità al 12,7%).
Se ne ricava quindi che il numero di casi che abbiamo in realtà in Liguria è molto più grande ed anche molto più grande di quanto stimato sfruttando l’analisi dei dati Cinesi o Coreani. Pur avendo aumentato il numero di test effettuati, questi non sono cresciuti in proporzione alla progressione del contagio e rilevano quindi solo una piccola parte degli infetti reali, tagliando probabilmente fuori la grande parte dei sintomatici e paucisintomatici (coloro che manifestano sintomi molto lievi).
Per poter concretamente, quindi, dire quanto tempo ci vorrà per poter uscire da questa situazione, dobbiamo effettuare stime e misurazioni più correte e coerenti sul numero reale di infettati.
Vedremo domani di valutare queste stime partendo da parametri più solidi e capire come le proiezioni, nei diversi casi, ci aiutano a valutare gli orizzonti.
Sorgenti e fonti consultate La mappa della nostra era glaciale: così il coronavirus ha congelato l’Italia – La Repubblica Online. Real estimates of mortality following COVID-19 infection (2020) https://github.com/pcm-dpc/COVID-19
Da anni cerco di impegnarmi per trasferire il valore del data driven alle organizzazioni con le quali collaboro. Oggi il mondo parla di Intelligenza artificiale partendo dal tema dell’apprendimento automatico (machine learning). Grazie all’enorme diffusione di dati estremamente vari e ricchi, sia per dimensione che per copertura e granularità, si possono fare analisi spesso semplici che possono portare grande valore ed aiutare decisioni informate e non basate su percezioni o esperienze pregresse (magari basate su situazioni diverse).
Fatta questa anticipazione, mi sono trovato qualche giorno fa nel mezzo dell’esplosione di questo fenomeno, dove l’Italia è stata il primo paese europeo colpito dell’epidemia di COVID-19. Abbiamo assistito ad una graduale diffusione del virus: prima in alcune zone della Lombardia, che ha portato inizialmente ad una zona rossa (10 comuni lombardi ed 1 veneto) il 23 febbraio2020 , quindi alla chiusura delle scuole in 6 regione italiane il 25 febbraio 2020, per arrivare all’8 marzo 2020 all’estensione della zona rossa all’intera Lombardia con l’aggiunta di diverse province del Piemonte, Emilia-Romagna, Veneto e Marche. Il 9 marzo un ulteriore decreto restrittivo definiva il lockdown nell’intera nazione, ed il 12 marzo un ultimo decreto riduceva l’apertura degli esercizi commerciali.
Nel contempo l’analisi dei primi dati e del progresso del contagio ha portato il Dipartimento della Protezione Civile (DPC) a rilasciare comunicati ed informazioni strutturate e, dopo alcune iniziative di informatici e data scientist, a rilasciare un repository GitHub con tutti i dati ufficiali aggiornati in formato machine readable. Qui un plauso al DPC, perché condividere contenuti è di grande valore, specie nell’esigenza di avere informazioni rapide e affidabili. Averle condivise in un repository pubblico ed accessibile ha fatto sì che diversi contributori aiutassero a definire meglio, correggere errori e proporre migliorie.
Dai nostri dati italiani, aperti e disponibili, si sono potute fare dashboard con maggiori capacità di informazione e di interazione come questa, realizzata dall’amico Andrea Benedetti di Microsoft. Anche Andrea, dopo una prima realizzazione “di corsa”, ha aperto un repository GitHub ed ha ricevuto il supporto di diversi professionisti IT che l’hanno fatta crescere e migliorare, e, soprattutto ,si è potuto cominciare a fare delle previsioni o proiezioni credibili, sia per capire la crescita di questo fenomeno che per definire o confermare parametri che sono e saranno fondamentali per la sua gestione futura.
L’idea che è maturata quindi il 9 marzo scorso, con il lockdown in Italia e che è stata condivisa con il Data science seeddi Genova è stata:
Riusciamo a prevedere l’andamento di questo fenomeno in Liguria (la regione nella quale viviamo e che ha l’età media (48,5 anni) più alta d’Italia)?
Riusciamo a determinare la quantità di posti letto di rianimazione necessari?
Quando questo fenomeno finirà o ridurrà la necessità di misure restrittive e contenitive?
Avevamo a disposizione molti dati per trovare un modello matematico che potesse fittare (quindi adeguarsi ai dati esistenti), anche se mancavano ancora parecchie informazioni. Abbiamo quindi cominciato a cercarle anche chiedendo gli amici cinesi, che avevano già vissuto il fenomeno, e che sono stati rapidi e prodighi di informazioni e studi pubblicati (Grazie!). Cerchiamo ora, a nostra volta, di condividere risultati e informazioni che cercheremo di strutturare meglio e produrre su repository aperti.
Undocumented cases: Diversi studi (riportati al termine del BLOG), con modalità differenti, hanno stabilito un parametro comune sui casi undocumented (pazienti infettivi non rilevati). In questa patologia virale, la gran parte delle persone contagiate è asintomatica, o con sintomi molto lievi che possono facilmente essere confusi con patologie comuni. Questo fa si che sia presente una grande quantità di contagiati, comunque infettivi, che non sapendo di esserlo favoriscono la progressione del contagio e non vivono le prime misure di contenimento (Quarantene). Si è cercato di stabilire quale fosse la quantità di questi contagiati, ed il parametro che si ricava da due diversi studi è che al 95%, la percentuale di undocumented è tra 82% e 90%, (o nell’altro caso 81,8%-89.8%), quindi con una mediana all’86.2%. Ciò significa che, il numero dei casi rilevati (ad esempio a ieri in Italia ne avevamo 47.021) rappresenta, in media, solamente il 13.8% dei casi realicontagiosi (applicando la proiezione all’Italia, nella giornata di ieri avremmo potuto rilevare 335.000 casi infettivi)
Tempo di incubazione: Inizialmente questo fenomeno è stato confuso con influenze stagionali. L’unico modo per rilevarlo con certezza è quello di effettuare un test apposito (PCR Test), che è stato realizzato e perfezionato dopo due settimane dalla prima identificazione, della malattia. La Cina, dopo il primo periodo, nel quale ha gestito l’insorgenza dell’epidemia cercando di limitarla, ha fatto un uso estensivo di Big Data ed AI ed ha cominciato un programma di screening intensivo che gli ha consentito di definire in maniera più precisa il tempo di incubazione. La China National Health Commission (NHC) ha stimato quindi inizialmente un periodo di incubazione variabile tra i 10 e i 14 giorni. In questi giorni, diversi enti stanno rilasciando la loro stima sui dati (è difficile in questa fase non controllabile stabilire il momento iniziale di esposizione all’agente virale). Il WHO riporta che il periodo può andare dai 2 ai 10 giorni, mentre l’US CDC definisce dai 2 ai 14 giorni. Questo significa che, se prendiamo una mediana di 5,1 giorni, dovremmo rilevare gli effetti delle misure restrittive al movimento in media dopo tale periodo. Il 97,5% di coloro che ha sviluppato sintomi, comunque, lo ha fatto entro 11,5 giorni dall’infezione (quindi dopo questo periodo, gli effetti delle misure restrittive dovrebbero essere evidenti e significativi)
Tempi di decorso della malattia e ricovero in terapia intensiva (ICU) Per poter stabilire con maggiore precisione il numero dei letti in terapia intensiva necessari, era necessario conoscere i tempi medi di decorso della malattia: dall’insorgenza dei primi sintomi, alla dispnea, al ricovero in terapia intensiva, fino al termine del ricovero (decesso o sopravvivenza). Purtroppo non siamo riusciti ad ottenere un dataset disaggregato, questo avrebbe aiutato a raffinare ed adeguare le previsioni, ma uno studio recente pubblicato su Lancet identifica un parametro medio aggregato che consente di stabilire quanto tempo rimarrà mediamente occupato un letto in terapia intensiva per un paziente COVID. In media, come tempo di occupazione abbiamo 7,5 gg per coloro che guariscono, e di 6,5 gg per i deceduti. Su questo parametro sarebbe necessaria una valutazione No stress / Under stress del sistema sanitario, sia per rilevare a quale stadio del decorso vengono in media ospedalizzati i pazienti (è ragionevole pensare che sotto stress gli accessi in ospedale vengano ridotti per capienza), che per rilevare la varianza nei tempi di permanenza in terapia intensiva.
Significatività e clustering Regione Liguria aveva identificato il primo caso il 25 febbraio 2020 (dal Dataset DPC), controllando le notizie sembra si riferisse ad una turista proveniente dal lodigiano (prima zona rossa). Il caso era nella provincia di Savona (Alassio). La domanda a quel punto è: quanto può essere significativa una proiezione su una regione che, per quanto limitata come superficie, conta 1,55 mln di abitanti, specie considerando che la maggiore concentrazione di questi abitanti è nell’area metropolitana di Genova? Sappiamo però che, in realtà, il numero dei contagiati in quella data era ben più alto: Considerando il periodo di incubazione, e la percentuale degli undocumented, possiamo stimare quindi il numero dei contagiati infettivi, al 25 febbraio a 150 casi. (Si verificano i dati del totale positivi al primo di marzo, 21 casi, e si considera che questi sono, in media il 13,8% dei casi totali effettivamente contagiosi). Il cluster è quindi già significativo, e la mobilità sicuramente più ridotta (Un solo aeroporto regionale e due stazioni ferroviarie importanti) ci da elementi per fare una buona previsione.
Modellazione all’11 di marzo Una volta raccolti questi parametri, avevamo il dataset del DPC per la Regione Liguria, che, all’11 di marzo, identificava 181 pazienti positivi, dei quali 108 ospedalizzati(56%), dei quali 34 (31% degli ospedalizzati, 19% dei casi totali) in Terapia intensiva. Avevamo quindi la progressione dal 25 febbraio all’11 di marzo e si poteva cominciare a stabilire la curva che meglio si adattasse a questo andamento per definire il modello matematico della crescita. La curva più adatta, per i fenomeni epidemici, è una curva logistica della quale era possibile stabilire il tasso di crescita:
La differenza di casi nel tempo si ottiene facendo crescere i casi giornalmente (unità di tempo) per un fattore (r), limitando la crescita nel momento in cui il numero di potenzialmente infettabili diminuisce (perché sono stati tutti infettati, guariti, deceduti). In realtà il calcolo è molto più semplice di quanto l’equazione suggerisca ai non matematici: Nel nostro caso andiamo a variare il parametro fino a quando questo non “fitta” con l’andamento che avevamo a quel tempo:
Totale Casi in Liguria all’11 marzo – Fonte Dataset DPC all’11 marzo.
Stabilito il parametro di crescita (1,20419), e valutato che, anche considerando tempo di incubazione (+6 giorni) e casi non documentati (86,2% del totale), si stavano stimando 5.136 casi, quindi lo 0,32% della popolazione Ligure, potevamo proiettare i giorni successivi sapendo che la crescita non sarebbe stata limitata, e la pendenza sarebbe stata coerente almeno fino al 17/19 di marzo, dato che le misure prese il 9 marzo e il 12 marzo non avrebbero avuto effetto nei numeri visto il tempo di incubazione stimato.
Previsione del totale casi in Liguria al 19 marzo (su dati dell’11 marzo)
A quel punto si poneva la scelta di modellare gli altri parametri: Ospedalizzati, ammessi in terapia intensiva, guariti e deceduti. C’erano diverse scelte che avevano tutte diverse suscettibilità: Avremmo limitato il numero di test effettuati (Diventa difficile farlo a tutti al salire dei casi)? (aumentando quindi la percentuale relativa di ospedalizzati?) Avremmo variato, per scelta o per necessità, le politiche di ammissione ospedaliera? Avremmo variato il tempo di permanenza in Terapia Intensiva? La scelta finale è stata quella di modellare analogamente la curva, ma prevedendo degli aggiustamenti sulle percentuali identificate in Cina nella provincia di Hubei (quella di Wuhan). Sulla base di questo sono state generate le proiezioni di:
Ospedalizzati (Curva specifica adeguata)
Terapia Intensiva (Calcolando che il numero viene decrementato delle ammissioni avvenute 9 giorni prima)
Deceduti (curva statistica)
Previsione della progressione in Liguria di COVID 19 a Marzo 2020.
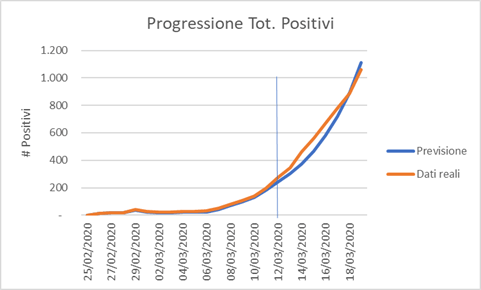
Ora, a distanza di circa 10 giorni dalla previsione possiamo verificare l’adeguatezza del modello e capire qualche elemento in più:
Crescita e progressione
Verifica (Empirica e statistica) della media del tempo di incubazione definito
Indicazione su tempi medi di degenza in terapia intensiva
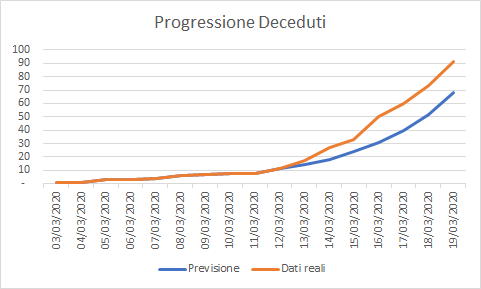
Confronto previsione / casi reali COVID-19 in Liguria al 20 di marzo
Confronto previsione / Ospedalizzati reali COVID-19 in Liguria al 19 di marzo
Confronto previsione / Terapia Intensiva reali COVID-19 in Liguria al 19 di marzo
Confronto deceduti previsti / reali COVID-19 in Liguria al 19 di marzo
Il maggior numero di decessi è legato probabilmente all’età media della popolazione ligure (la più alta d’Italia) stante i tassi di mortalità rilevati in Cina per età e patologie pregresse. Il maggior numero di decessi, dall’altra parte, compensa quasi esattamente il minor numero di posti di rianimazione necessari (per quanto non si può derivare una correlazione stretta su questa numerica limitata e, comunque, stimata).
Si vede inoltre come, per almeno 10 giorni dall’entrata in vigore delle prime misure restrittive del 9 marzo, e ad almeno 7 giorni dall’entrata in vigore delle misure maggiormente restrittive del 12 marzo, non si rileva alcuna diminuzione nella progressione del contagio. Si nota, ma è un singolo elemento, come il 20 di marzo, il numero totale dei casi in Liguria era di 1.221, contro i 1.377 invece previsti, quindi una riduzione molto significativa, che si attende di confermare nella giornata odierna. Questo potrebbe suggerire un primo impatto delle misure restrittive del 9 marzo (e quindi un tempo medio di incubazione di 11 giorni, come suggerito dalle analisi fatte in Cina), oppure un impatto delle misure del 12 marzo.
Nei prossimi giorni cercherò di riportare analoghe valutazioni su quelle che potrebbero essere le previsioni per il futuro, sia in termini di sviluppo della curva che in termini di potenziale riduzione delle misure di distanziamento sociale. Grazie per ogni commento o integrazione che, se necessario, integrerò anche nella versione inglese del post.
Articoli e fonti consultate: – Vital Surveillances: The epdemiologica Characteristics of an Outbreak of 2019 Novel Coronavirus Diseases (COVID-19) – China 2020 – Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: a retrospective cohort study – Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV2). (2020) – https://github.com/CSSEGISandData – https://zenodo.org/record/3699624#.XnX2nohKgaZ – https://www.worldometers.info/coronavirus/coronavirus-incubation-period/ – https://github.com/pcm-dpc/COVID-19 – Real estimates of mortality following COVID-19 infection (2020) – Effect of delay in diagnosis on transmission of COVID-19 (2020) – Insights from early mathematical models of 2019-nCoV acute respiratory disease (COVID-19) dynamics
Crescere da informatico nell’era di Hollywood non è stato per niente facile! Vedere al cinema tutte queste fantastiche distorsioni ha sempre colpito e suscitato più di un sorriso: Ricordo ancora l’indirizzo IP sbagliato di “The Net”, o i colorati multischermi di “Codice swordfish”. Una cosa però che mi faceva sempre arrabbiare era quella frase, tipicamente detta dallo sveglio analista della CIA all’esperto, un po’ nerd, che utilizzava il computer: “Puoi ingrandirlo?” Ed ecco li che, come per magia, l’immagine compariva perfettamente definita! E si scopriva l’ombra, la macchia, o il dettaglio che consentiva alla trama di andare avanti, mentre tu mormoravi sommessamente con fare vagamente competente: “Se l’informazione non c’è, mica il computer può inventarla“
Tutto questo è vero, ma non lo è più nella sostanza. Qualche anno fa un articolo interessante faceva notare come in un lavoro di Google si fosse riusciti ad ottenere una predizione molto vicina al reale (Ground truth) di come fosse un’immagine da un insieme quasi indistinto di Pixel. Era un lavoro di super upscaling sfruttando tecniche di AI che forniva elementi interessanti e nuovi casi d’uso delle reti neurali.
Nel contempo il tema dell’upscaling diventava sempre più rilevante: I televisori cominciavano a diventare a 4K ed ora ad 8K e servivano tecnologie sempre più qualitative ed affidabili per rendere contenuti prodotti a risoluzioni inferiori presentabili alla qualità più alta.
Esistono molti siti e software che effettuano questi piccoli miracoli, sfruttando reti neurali deep: da GigaPixel AI al gratuito (ed ancora in beta) DeepImage AI. Questi strumenti consentono di prendere immagini di scarsa qualità e trasformarli in foto di qualità invece elevatissima, consentendo di definire anche particolari molto piccoli di foto, oppure migliorare la qualità di foto molto vecchie.
Esempio di trasformazione con Topaz Gigapixel AI
L’AI Upscaling ha la capacità di produrre risultati qualitativamente molto superiori ed anche più vicini alla realtà del suo equivalente tradizionale basato su metodi trigonometrici. Nvidia ha prodotto un dispositivo (Nvidia Shield) che consente di fare streaming di contenuti anche a 720p su televisori 4K sfuttando AI, ed ha realizzato questo sito per mostrare la differenza tra un upscaling tradizionale, che si trova nella maggior parte dei televisori, ed uno basato su AI.
Fin qui tutto bello: le foto del matrimonio della nonna ora possono sfavillare in tutto il loro splendore come fossero state scattate ieri! Nel contempo, un ragazzo russo, utilizzando anche un altro strumento, gratuito e disponibile: Dain (frutto di un lavoro molto bello dell’università di Shangai), grazie al quale si generano anche le interpolazioni dei frame di un video per aumentare il suo frame rate. Ha applicato entrambe queste tecniche (AI Upscaling e Frame interpolation) per dare nuova vita ad un video del 1896: L’arrivo del treno nella cittadina di La Ciotat.
Il risultato è impressionante dal punto di vista visivo. Forse non così sorprendente se si conoscono le tecniche ed il loro potenziale, ma utile per far comprendere semplicemente come l’AI sia già molto disponibile (e spesso anche gratuita!). Un video del 1896 è ora disponibile in 4K di risoluzione e con un frame rate da 60 FPS, una qualità degna degli strumenti di registrazione più moderni direttamente da 124 anni fa…
Questo è il risultato delle elaborazioni:
Mentre qui sotto ho reperito la versione originale dei fratelli Lumière.
Pensate a cosa è possibile fare, con tecnologia accessibile, magari gratuita, che può essere resa facilmente disponibile grazie al Cloud computing: Investigazioni più efficaci (stavolta davvero!), analisi satellitari (Ne parleremo), restauri artistici e…. Come spesso accade, il limite è nella creatività con la quale applicheremo queste tecniche in futuro!